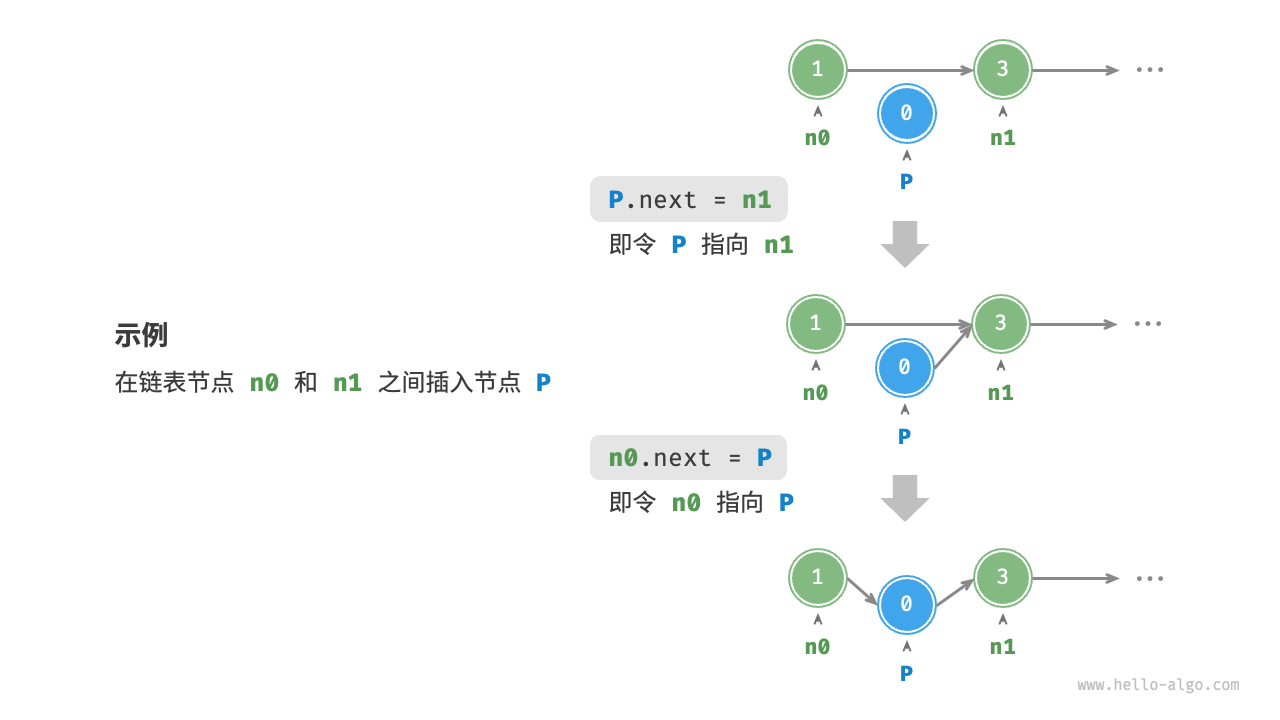
definsert(nums: list[int], num: int, index: int): """在数组的索引 index 处插入元素 num""" # 把索引 index 以及之后的所有元素向后移动一位 for i inrange(len(nums) - 1, index, -1): nums[i] = nums[i - 1] # 将 num 赋给 index 处的元素 nums[index] = num
删除元素
把索引 index 及以后的所有元素向前移动一位
1 2 3 4 5
defremove(nums: list[int], index: int): """删除索引 index 处的元素""" # 把索引 index 之后的所有元素向前移动一位 for i inrange(index, len(nums) - 1): nums[i] = nums[i + 1]
遍历数组
通过索引
直接遍历
同时遍历索引和数据 enumerate()
1 2 3 4 5 6 7 8 9 10 11 12 13
deftraverse(nums: list[int]): """遍历数组""" count = 0 # 通过索引遍历数组 for i inrange(len(nums)): count += nums[i] # 直接遍历数组元素 for num in nums: count += num # 同时遍历数据索引和元素 for i, num inenumerate(nums): count += nums[i] count += num
查找元素
遍历+判断
1 2 3 4 5 6
deffind(nums: list[int], target: int) -> int: """在数组中查找指定元素""" for i inrange(len(nums)): if nums[i] == target: return i return -1
扩容数组
原因:数组的长度是不可变的
初始化+复制粘贴
1 2 3 4 5 6 7 8 9
defextend(nums: list[int], enlarge: int) -> list[int]: """扩展数组长度""" # 初始化一个扩展长度后的数组 res = [0] * (len(nums) + enlarge) # 将原数组中的所有元素复制到新数组 for i inrange(len(nums)): res[i] = nums[i] # 返回扩展后的新数组 return res
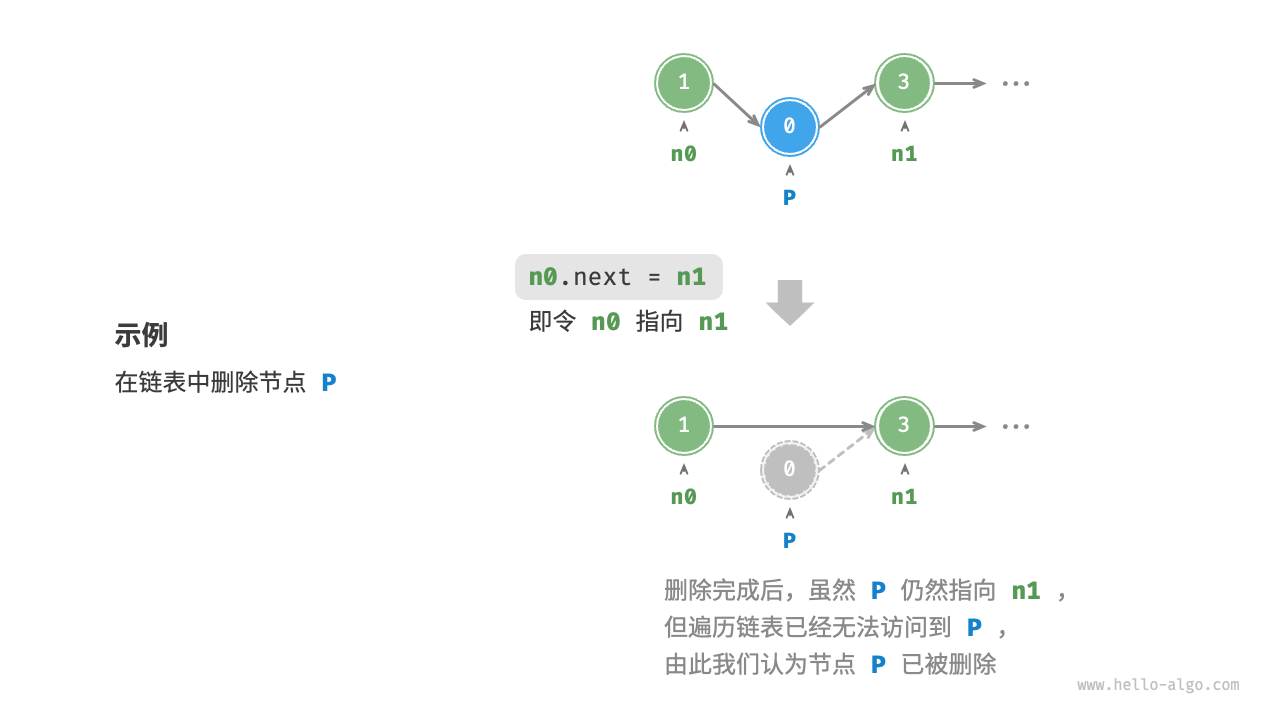
defaccess(head: ListNode, index: int) -> ListNode | None: """访问链表中索引为 index 的节点""" for _ inrange(index): ifnot head: # 检查当前的 head 节点是否为 None,链表末尾或者链表为空 returnNone head = head.next return head
查找节点
遍历
1 2 3 4 5 6 7 8 9
deffind(head: ListNode, target: int) -> int: """在链表中查找值为 target 的首个节点""" index = 0 while head: # head = None 不进行循环 if head.val == target: return index head = head.next index += 1 return -1